NIM : 2301862393
Name: Joerio C.
POINTER
Pointer is a data type whose value refers to another value stored elsewhere in a computer memory using its address.
This computer memory is what we more know as Random Access Memory or RAM.
And every compiler or intrepreter has different ways to access its memories.
Why does C uses operator "&" to scan or read a data?
- to store the memory in an anddress
- to determine which position the data is stored in
There are a lot of things that use pointers, especially in the complex data structures field. Some of the many applications are:
1. Trees
2. Linked List
3. Stack
4. Queue
5. Graphs
Pointers are also used for the dynamic memory allocation of a variable.
An example of pointer variables in C:
int x;
int *px; //pointer variable of x
px = &x;
to assign a value of x we can write:
x = 10; or *px = 10;
Another example:
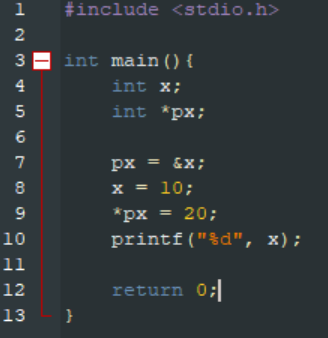
Output: 20
The value of x is changed to 20 in "*px = 20;", because px was assigned to be the address of x in "px = &x ' which makes pointer px (*px) equal to x -- they are interconnected now.
To understand more about this, here is a visualization that explains about the correlation between a variable, its memory, and its address (the concept of pointer):
Code:
int x;
int *ptr;
ptr = &x;
Explanation:
x:
- memory: (blank)
- address: 2345
ptr:
- memory: 2345
- address: 5000
Notice that the address to variable x is also the memory to pointer variable ptr and ptr has a different address than x, which is why we can make a pointer to that pointer variable that is also known as pointer to pointer.
Pointer to Pointer:
int x = 10;
int *px; //pointer to x
int **ppx; //pointer to pointer of x
px = &x;
ppx = &px;
Now, if the address of x (or &x) is 1002, then the value to pointer to x (px) is 1002.
And if the address of the pointer to x (px) is 2004, then the value to pointer to pointer to x (ppx) is 2004. In other words, ppx stores the address of px, while px stores the address of x.
ARRAY
Array is a collection of homogenous data items stored in a contiguous memory locations. For example, if we declare an array with the data type of 'int', then the whole data that we store has to be of type 'int' or else it would not be stored or an error will occur.
To declare an array variable, we can use:
int arr[10];
This is an array of data type integer, which means it can only store integers only. Values like decimals will not be stored as decimals as it will automatically be rounded by our compiler to from the data type of integer.
Also, this array variable arr can store up to 10 different data, because when we first declared it on the code above to have a size of 10 in '[10]'. But, we can store as many data as we need so long as our computer's memory is capable of doing so.
A visualation of array of integers:

Linked List
Linked List is a data structure that consists of a sequence of data records such that each record there is a field that contains a reference to the next record.
Linked list is used in many algorithms for solving real-time problems, when the number of elements to be stored is unpredictable and/or during sequential access of elements.
There are 2 types of linked list:
1. Single linked list

2. Double linked list

Single linked list has a pointer most people call *next to connect one node to the next node, so does double linked list. The only difference is that double linked list also has a pointer that connects a node to the previous node behind it which most people call *prev.
Linked lists have what we call the pointer head and pointer tail. The head is basically the first data in the linked list, while tail is the last.
Linked lists have the same function as arrays other than the *next and *prev pointers. In addition to that, there are some more major differences that distinct an array to a linked list.
- Array:
- is a linear collection of data elements
- stores value in consecutive memory locations
- can be random in accessing data
- Linked List:
- is a linear collection of nodes
- stores value in random memory locations
- accesses data only in sequential manner
To use linked list in the C language, we need the malloc.h or stdlib.h library mainly for the memory allocation function, which is malloc() itself. The purpose of this malloc function is to allocate memories dynamically (in run-time). To deallocate the memories used, we can use the function free(). We deallocate memories so that our computer can use that memory for other programs if needed.
Example:

Now if we want to free the head, we can use the function free():
Stack
Stack operations:
- push: add an item x to the top of the stack (enstack)
- pop: remove an item from the top of the stack (destack)
- top/peek: reveal/return the top of the stack
Infix, Prefix, Postfix
Stack is applied for mathematical equations. When we input a normal equation (called an infix), the computer reads it and converts the equation into a prefix or postfix for easier computation due to having no brackets to show precedence or priority of the operators.
Infix: 4 * 5
Prefix: * 4 5
Postfix: 4 5 * ( scans from left to right, has the complexity of O(N) )
An example of how infix is converted into postfix using stack:
A * B + C becomes A B * C +

Hashing
Hashing is some kind of data structure used to store many data using mapping and the function called Hash function. The Hash function is used to store a value in the map provided that the user gives the key to that value.Hash function's format: Hash(key) → index
Supposed we want to make a phonebook using the Hashing. The data that we store are phone numbers, these are the values that the Hashtable will later commit into memory. Say that we want to store Bob's phone number into the phonebook's index number 1, then we would write the Hash function as such: " Hash(Bob) → 1 ". In this case, Bob is the key that can only be used to access his index in the mapping.
Hashing is almost like Linked List. The difference is that we can store multiple data into the same index, which we call the Hash Chain. Once we have the key and the index, then it is not very complicated to find somebody else's phone numbers even though it is stored in the same index as Bob here. As you can see in the picture below.
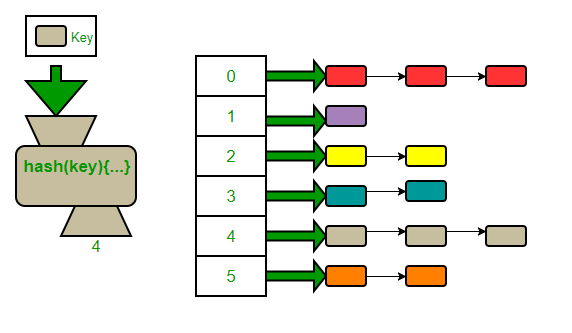
Image source: geeksforgeeks.org
The vertical white boxes containing the numbers 0-5 is what we call the Hashtable, while the horizontal colored boxes are what we call Hash Chain.
Now, the process in which Hash Chains are created are called collision. To further explain what a collision is, we can imagine buying a new phonebook. In that phonebook, we want to list all our friends' phone numbers ascending according to the first letter of their names.
For example, we have Alan, Henry, Jaka, and Jono. Let's say we have 26 indexes in our book, which are sorted alphabets (from A to Z). And here is how we sort them:
- The first letter of Alan's name is 'A', which is the 1st letter of the alphabets. So, we simply put his name into the 1st index of our phonebook.
- Next, we have Henry whose first letter of his name is 'H', which is the 8th letter of the alphabets. That is why we are putting Henry in the 8th index.
- Then, we have Jaka and Jono that both name starts with 'J'. Following the rules above, we are placing Jaka and Jono into the 10th index of our phonebook. But, how can we possibly fit 2 names into the same index? This is what we precisely call as a collision. And to handle such problem, we use linked list in order to store these two names into one index. So now, the 10th index of our phonebook has Jaka and then Jono, who is connected with linked list (visualization: "10. Jaka → Jono").
When we were trying to figure out which index they belong to in the illustration above, we call it as finding our key. Alan has the key of 1; Henry has the key of 8; Jaka and Jono both have the keys of 10. And to further make us understand on how to find our hashtable key, study the code of the getHashKey() function written in C compiler below:

How is Hashing utilized in the current Blockchain technology?
In Blockchain, every block has a hash of the previous block. The previous block of our current block is called as the parent block.
According to a Blockchain developer, every block in the Blockchain has a hash of the previous block. If we change any data in the current block, the hash of the block will be changed. This will affect the current block, because the current block has the address of the previous block. They are interconnected to each other. In other words, we have to change the data in the current block, then we also have to change the data in our parent block. (note: current block is also called present block)
Binary Tree
A Binary Tree is a special type of tree in which every node or vertex has up to 2 child nodes. The starting node is called the root node. There are 2 terms to refer to child nodes (corresponding to which side of the node it is branching to): the left child node & the right child node. The nodes without any child node branching from it are called the leaf nodes.
Image source: javatpoint.com
Binary Trees can be represented in 2 ways: using Arrays or using Linked Lists.
There are 2 types of Binary Trees:
1. Full Binary Tree / Proper Binary Tree / 2-tree: a tree in which all the node has exactly two children, except for the leaf nodes.
2. Complete Binary Tree: a binary tree in which at every level, except possibly the last, has to be filled and all nodes are as far left as possible.