AVL Tree & B-Tree
AVL Tree
Definition
AVL tree is a data structure that, as the name suggests, is created by two Soviet inventors by the names of Georgy Adelson-Velsky (AV) and Evgenii Landis (L). They published this in their 1962 paper titled "An Algorithm for the Organization of Information".
In computer science, the AVL tree is the first ever tree that is self-balancing, because when the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, a recursive function is done to rebalance this property.
It takes O(log n) time complexity for search, insertion, and deletion, where n is the number of nodes in the tree. Sometimes, insertion and deletion require the tree to be rebalanced by one or more tree rotations.
Here is an example of an AVL tree with balance factors (green):

Source: wikipedia.org
Balance Factor
In a binary tree, the balance factor of a node n is defined to be the height difference of its two child sub-trees in the following formula:
BalanceFactor(n) := height(RightSubtree(n)) - height(LeftSubtree(n))
A binary tree is considered an AVL tree when the invariant holds for every node n in the tree.
BalanceFactor(n) ∈ {-1, 0, 1}
A node with BalanceFactor(n) < 0 is left-heavy, while BalanceFactor(n) > 0 is right-heavy, and BalanceFactor(n) = 0 is balanced.
Operations
Operations of an AVL tree has the same actions as the operations carried out on an unbalanced BST (binary search tree). But the modifications have to observe and restore the height balance of sub-trees.
Searching
In AVL, searching for a key is carried out the same way as in BST (binary search tree).
The search in AVL require the employment of a comparison function that establishes a total order (or preorder) on the set of keys. This has the time complexity of O(log n).
Insert
When inserting a node into a tree, we use the same method as in BST. If the tree is still empty, then the node becomes the root of the tree. If the tree is already occupied, then we go down recursively from the root searching for the compatible location to insert the new node. This traversal is guided by the comparison function. In this case, the node always replaces a NULL reference (left or right) of an external node in the tree, either becoming a left-child or right-child.
After this insertion if a tree becomes unbalanced, only ancestors of the newly inserted node are unbalanced. This is because only those nodes have their sub-trees altered. So it is necessary to check each of the node's ancestors for consistency with the invariants of AVL trees: this is called "retracing". This is achieved by considering the balance factor of each node. If a tree becomes unbalanced due to the insertion of a value, then the tree will apply some rotations in order for it to be rebalanced.
Delete
In deletion, the properties of an AVL tree have to stay the same so that it will not become any other kind of trees. To delete a root node from the tree, we have to replace the root with the rightmost child of the left sub-tree. After the replace, we consider the balance factor and then we have to rebalance the tree if it is not balanced.
B-Tree
Delete
In deletion, the properties of an AVL tree have to stay the same so that it will not become any other kind of trees. To delete a root node from the tree, we have to replace the root with the rightmost child of the left sub-tree. After the replace, we consider the balance factor and then we have to rebalance the tree if it is not balanced.
B-Tree
Definition
B-Tree is another self-balancing tree data structure and it is not the abbreviation for Binary Search Tree, so do not confuse them together. It is invented by Rudolf Bayer and Edward M. McCreight while working at the Boeing Research Labs when they were trying to optimize managing index pages for large random access files.
Like other self-balancing trees, B-Trees have the time complexity of O(log n) when doing search, insertion, and deletion. Unlike any other self-balancing tree data structures though, B-Tree is the most suitable for storage systems that read and write large blocks of data, such as discs, and is commonly used in databases and file systems. What makes B-Tree unique to other trees is that one node can contain more than two data or degrees and can have more than two children. Other than that, B-Tree grows and shrinks from the root, which separates it from Binary Search Tree (which grows and shrinks from downward).
Properties
The properties of a B-Tree of order n is as follows:
1. Every node has at most n children.
2. Every non-leaf node (except root) has at least [n / 2] child nodes.
3. The root has at least two children if it is not a leaf.
4. A non-leaf node with k children contains [k - 1] keys.
5. All leaves are at the same level and carry no information.
Operations
Search
The search algorithm is similar to the one in BST. We start from the root and recursively traverse down (similar to BST's inorder traversal). For every visited non-leaf node, we recur down until it finds the key of the node. If we do not find the key from any leaf node, then we return NULL.
Insert
Insertions can be very slow in a sorted sequential file because room for the inserted record must be made. Inserting a record before the first record requires shifting all the record down by one level. One solution in insertions is to leave some spaces. Instead of densely packing all the records in a block, the block can have some free space to allow for subsequent insertions. Those spaces would be marked as if they were "deleted" records.
These are the simplified steps for insertion algorithm according to geeksforgeeks.org:
1) Initialize x as root.
2) While x is not leaf, do the following:
3) The loop in step 2 stops when x is leaf. x must have space for 1 extra key as we have been splitting all nodes in advance. So, simply insert k to x.
Delete
In deletion, the index of the B-Tree can stay the same and the record can just be marked as "deleted". The database will remain sorted.

Insert 6
Insert 7







Delete 8


Insert 6

Insert 7

Insert 0

Insert 4

Insert 3
Insert 8

Delete 3

Delete 4

Delete 8

Like other self-balancing trees, B-Trees have the time complexity of O(log n) when doing search, insertion, and deletion. Unlike any other self-balancing tree data structures though, B-Tree is the most suitable for storage systems that read and write large blocks of data, such as discs, and is commonly used in databases and file systems. What makes B-Tree unique to other trees is that one node can contain more than two data or degrees and can have more than two children. Other than that, B-Tree grows and shrinks from the root, which separates it from Binary Search Tree (which grows and shrinks from downward).
Properties
The properties of a B-Tree of order n is as follows:
1. Every node has at most n children.
2. Every non-leaf node (except root) has at least [n / 2] child nodes.
3. The root has at least two children if it is not a leaf.
4. A non-leaf node with k children contains [k - 1] keys.
5. All leaves are at the same level and carry no information.
Operations
Search
The search algorithm is similar to the one in BST. We start from the root and recursively traverse down (similar to BST's inorder traversal). For every visited non-leaf node, we recur down until it finds the key of the node. If we do not find the key from any leaf node, then we return NULL.
Insert
Insertions can be very slow in a sorted sequential file because room for the inserted record must be made. Inserting a record before the first record requires shifting all the record down by one level. One solution in insertions is to leave some spaces. Instead of densely packing all the records in a block, the block can have some free space to allow for subsequent insertions. Those spaces would be marked as if they were "deleted" records.
These are the simplified steps for insertion algorithm according to geeksforgeeks.org:
1) Initialize x as root.
2) While x is not leaf, do the following:
- Find the child of x that is going to be traversed next. Let the child be y.
- If y is not full, change x to point to y.
- If y is full, split it and change x to point to one of the two parts of y. If k is smaller than mid key in y, then set x as the first part of y. Else second part of y. When we split y, we move a key from y to its parent x.
3) The loop in step 2 stops when x is leaf. x must have space for 1 extra key as we have been splitting all nodes in advance. So, simply insert k to x.
Delete
In deletion, the index of the B-Tree can stay the same and the record can just be marked as "deleted". The database will remain sorted.
Exercise:
* insert: 5,6,7,0,4,3,8
* delete: 3,4,8
* delete: 3,4,8
AVL Tree
Insert 5
Insert 6

Insert 7

Insert 0
Insert 4

Insert 3
Insert 8

Delete 3

Delete 4
Delete 8
B-Tree
With max degree of 3:
Insert 5
Insert 6
Insert 7
Insert 0
Insert 4
Insert 3
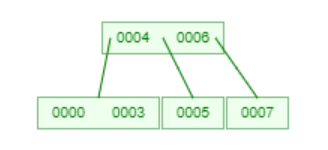
Insert 8

Delete 3

Delete 4
Delete 8